. @christianp has turned into a one-man plug for the holes in Wolfram Alpha. I’m genuinely impressed.
— Colin Beveridge (@icecolbeveridge) February 28, 2015
For a while, I’ve been following this cool Twitter account that tweets questions Wolfram|Alpha can’t answer. The genius of it is that the questions all look like things that you could half-imagine the solution algorithm for at a glance, and many of them look like the kinds of questions Wolfram like to give as examples when they’re showing off how clever their system is.
Questions like this:
number of words between "landslide" and "Beelzebub" in Bohemian Rhapsody
— Wolfram|Alpha Can't (@wacnt) January 22, 2015
The answer to that is 278. How do I know that? I know that because I went on a little problem-solving binge answering the questions that Wolfram|Alpha can’t.
Ever since I discovered the @wacnt account, a little voice had been telling me that I should work out the answers to some of the questions. While there are a few that require a good chocolate doughnut or two’s worth of brain power, the majority boil down to simple “look up some facts and put them together” tasks of the sort that Wolfram|Alpha is supposed to be good at.
So, while my fiancée and I were watching some improving broadcasts, I worked my way through @wacnt’s tweets, picking out questions to answer.
Here’s what I came up with. For comparison, I’ve found a query that Wolfram|Alpha can answer from their examples page, to go with each question it couldn’t.
smallest positive integer radius of a sphere whose volume is within 0.0001 of an integer
— Wolfram|Alpha Can't (@wacnt) February 28, 2015
This one’s straightforwardly mathematical: compute $\frac{4}{3} \pi r^3$ until you get close enough to an integer. Here’s the code I put in IPython:
from itertools import count
from mpmath import pi,floor,ceil,mp
mp.dps = 50
for r in count(1):
v = pi*mp.mpf(r)**3 * 4/3
d = min(v-floor(v), ceil(v)-v)
if d<0.00001:
print(r)
break
It turned out I had to use the arbitrary-precision mpmath library once $r$ was big enough. Anyway, it turns out the answer is $12352$, because $\frac{4}{3} \pi \times 12352^3 = 7894060641354.0000039427674483175607644657112582764….$.
But Wolfram|Alpha can answer: maximize e^x sin y on x^2+y^2=1
last time the world population was a repunit
— Wolfram|Alpha Can't (@wacnt) February 27, 2015
This is going to involve modelling the world’s population. I thought it’d be something like an exponential function, but it turns out the rate the world’s population is increasing has been… decreasing. Or at least fairly steady. Wikipedia has a page on word population milestones, which includes this table:
| Population (in billions) | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Year | 1804 | 1927 | 1959 | 1974 | 1987 | 1999 | 2012 | 2026 | 2042 | |||||||||
| Years elapsed | –– | 123 | 32 | 15 | 13 | 12 | 13 | 14 | 16 | |||||||||
The world’s population is currently more than 7 billion but less than 7,777,777,777, so the last time the world’s population was a repunit was when it was 6,666,666,666. I could probably have looked up more accurate statistics than the table above, but I couldn’t be bothered. So, all things considered, I decided a cubic spline wouldn’t be a terrible model for population. I set up a cubic interpolation in scipy and used it to find the date corresponding to 6,666,666,666.
from scipy import interpolate
# data from http://en.wikipedia.org/wiki/World_population_milestones
years = [1804,1927,1959,1974,1987,1999,2011,2026,2042]
pops = [x*10**9 for x in [1,2,3,4,5,6,7,8,9]]
# cubic interpolation between milestones
tck = interpolate.splrep(pops,years,s=0)
# time when population was 6666666666, according to the interpolation
t=interpolate.splev([6666666666],tck)[0]
y = floor(t)
days = 365*(t-y)
print(t,y,days)
> (2006.7698638728784, 2006, 281.00031360062758)
So, 281 days into 2006.
months = [31,28,31,30,31,30,31,31,30,31,30,31]
[sum(months[:i]) for i in range(len(months))]
[0, 31, 59, 90, 120, 151, 181, 212, 243, 273, 304, 334]
… which is a little bit into October. I suppose I could’ve just divided by 30 to get that level of precision. Meh.
But Wolfram|Alpha can answer: France pop 2000 – France pop 1980
number of white pixels in an image of a Norwegian flag 1000 pixels tall
— Wolfram|Alpha Can't (@wacnt) February 18, 2015
Easy! Get a picture of the flag of Norway; scale it to 1000 pixels; count the white ones. Once again, Wikipedia has all I need.
{kind=link}
from PIL import Image
f=Image.open(r"2000px-flag_of_Norway.svg.png")
white = 0
scale = f.size[1]/1000.0
for r,g,b,a in f.getdata():
if (r,g,b)==(255,255,255):
white += 1
white/(scale*scale)
> 247337.65543628437
I’ll call that 247338. I reckon Wolfram would’ve done about as well as that. I suppose I could’ve looked up the rules for the construction of the Norwegian flag and work it out precisely, but again I went with “quick but roughly right”, which Wolfram often does.
But Wolfram|Alpha can answer: nearest paper sizes for a 5″x7″ photo
longest English word formed only with letters m through z
— Wolfram|Alpha Can't (@wacnt) February 17, 2015
I have a few word lists saved on my PC because I like to do stupid things with words, so this was easy.
import re
words = open('words.txt').read().split('\n')[:-1]
# regex recognising words which only use the letters m to z
r = re.compile('^[m-z]*$')
# filter words matching the pattern
mwords = [w for w in words if r.match(w)]
# sort in descending order of length
mwords.sort(key=len,reverse=True)
# print the longest word
print(mwords[0])
> 'nonsynonymous'
# actually, is there more than one word that long?
print([w for w in mwords if len(w)==len(mwords[0])])
> ['nonsynonymous']
# that's a rubbish word. What are the top 10?
print(mwords[:10])
> ['nonsynonymous', 'unmonotonous', 'unsynonymous', 'monosporous', 'monostomous', 'myxosporous', 'myzostomous', 'nonsupports', 'nontortuous', 'nontumorous']
It looks like the longest word is ‘nonsynonymous’, at 15 letters, but I didn’t like the fact it uses a prefix, so I reckoned ‘monosporous’, at 11 letters, was the first “proper” word.
But Wolfram|Alpha can answer: words with qsp
ratio of dots to dashes in Gulliver's Travels in International Morse Code
— Wolfram|Alpha Can't (@wacnt) February 15, 2015
I liked this one! First of all I had to get a copy of Gulliver’s Travels, then a list of the Morse Code equivalents of each letter, and mash those two together. Of course Project Gutenberg has a plain text copy of Gulliver’s Travels which worked perfectly after I removed the metadata and legalese, and my good friend Wikipedia has a chart of Morse Code letters and numerals. Once I had those, I could put them in Python:
{kind=link}
gulliver = open(r'gulliver.txt',encoding='utf-8').read()
letters = 'abcdefghijklmnopqrstuvwxyz1234567890'
morse = '.- -... -.-. -.. . ..-. --. .... .. .--- -.- .-.. -- -. --- .--. --.- .-. ... - ..- ...- .-- -..- -.-- --.. .---- ..--- ...-- ....- ..... -.... --... ---.. ----. -----'.split(' ')
# count the number of dashes in each letter
dashes = {letter:code.count('-') for letter,code in zip(letters,morse)}
# count the number of dots in each letter
dots = {letter:code.count('.') for letter,code in zip(letters,morse)}
# for every letter in Gulliver's travels, add up the dashes
ndashes = sum(dashes.get(l,0) for l in gulliver.lower())
# and do the same with dots
ndots = sum(dots.get(l,0) for l in gulliver.lower())
# ratio of dots to dashes
print(ndots/float(ndashes))
> 1.5240217474538633
# the raw totals
print(ndots,ndashes)
> 696577 457065
About 50% more dots than dashes! I wonder if that’s anything to do with the fact that the most common letters in the English language, E, T, and H, are encoded as ., -, and ….: a clear win for dots.
But Wolfram|Alpha can answer: most frequent two-word phrases in The Raven
total segment toggles as a 7-segment display counts up from 1234 to 6789
— Wolfram|Alpha Can't (@wacnt) February 13, 2015
This is the kind of thing a Project Euler question might ask you to calculate. I quickly came up with an outline of an algorithm:
- encode the patteron of lit segments for each digit
- for each pair of digits, count the number of differing segments
- run through the numbers 1234 to 6789, comparing digits with the same place value and adding up the number of differing segments.
"""
Layout:
0
1 2
3
4 5
6
"""
from itertools import product
segments = ['1110111','0010010','1011101','1011011','0111010','1101011','0101111','1010010','1111111','1111010']
toggles = {}
for a,b in product(range(10),repeat=2):
t = 0
for da,db in zip(segments[a],segments[b]):
if da!=db:
t += 1
toggles[(str(a),str(b))] = t
total = 0
for old,new in zip(range(1234,6789),range(1235,6790)):
for dold,dnew in zip(str(old),str(new)):
total += toggles[(dold,dnew)]
print(total)
> 20976
I did the layout in my head – I might have made a mistake! Anyway, the total I got says that on average $20976/(6789-1234) \approx 3.77$ segments change at each tick, which doesn’t seem unrealistic.
But Wolfram|Alpha can answer: nothing? I couldn’t find anything similar to this – use common knowledge about a system; track some property of it as it evolves – in the examples page.
the pair of neighboring countries whose ratio of birth rates is the greatest
— Wolfram|Alpha Can't (@wacnt) February 10, 2015
I was really pleased with this one – it looked like a really hard problem, involving staring at a world atlas and writing out lists of adjacencies, but Wikipedia’s countless fact-hoarders have made it really easy. There’s a page with a table of countries and their land or maritime neighbours (I wasn’t sure whether to include neighbours separated by a sea but, as you’ll see, it didn’t matter in the end) and a page with birth rate figures for each country.
It turned out a couple of places have national birth rates but aren’t really countries – for example, the West Bank – but apart from that it all worked flawlessly.
best = None
top = None
for c1, borders in bordering.items():
if c1 in birth_rates:
for c2 in borders:
# pairs.append((c1,c2))
if c2 in birth_rates:
r = birth_rates[c1]/birth_rates[c2]
if best is None or r>best:
best = r
top = (c1,c2)
print("{} and {}: {} ({} against {})".format(top[0],top[1],best, birth_rates[top[0]],birth_rates[top[1]]))
> Afghanistan and China: 3.7899159663865545 (45.1 against 11.9)
Wow, Afghanistan has a high birth rate! I was half-expecting somewhere absolutely tiny like Monaco or Vanuatu would have a surprisingly high birth rate, but the answer I got made sense.
But Wolfram|Alpha can answer: unemployment rate of country with largest population
number of different time zones in places where Portuguese is an official language
— Wolfram|Alpha Can't (@wacnt) March 1, 2015
A couple of things to consider with this one: how hard will it be to find the countries with Portuguese as an official language? What is a time zone – do I count places which are currently on the same offset from UTC but have different daylight savings rules as the same time zone, or different?
I found a very helpful page listing the countries which speak a variety of world languages, Portuguese included. It lists 10 “Portuguese Speaking Countries”, of which Macau is one. Macau isn’t a part of China, not really a sovereign nation, which caused me some consternation, but that was helpfully solved when I noticed the list of countries where Portuguese is an official language, just underneath.
After that, I just googled “<place> time zone”, and jotted down the names of the time zones belonging to each country; Google helpfully showed a little card with just the information I needed. Brazil is the only Lusophone country with more than one timezone – 3 in total – and two pairs of countries sit in the same time zone, so it turns out that there are 9 time zones containing countries where Portuguese is an official language.
| Country | Time zone(s) |
|---|---|
| Portugal | Western European (UTC+0) |
| Cape Verde | Cape Verde (UTC-1) |
| Guinea-Bissau | GMT (UTC+0) |
| Timor Leste | Timor Leste (UTC+9) |
| Angola | West Africa (UTC+1) |
| Equatorial Guinea | West Africa (UTC+1) |
| Brazil | Amazon (UTC-4), Brasilia (UTC-3), Fernando de Noronha (UTC-2) |
| Mozambique | Central Africa (UTC+2) |
| Sao Tome and Principe | GMT (UTC+0) |
But Wolfram|Alpha can answer: time in Tokyo
2 cities outside Egypt, the great circle path between which separates Alexandria from Cairo
— Wolfram|Alpha Can't (@wacnt) February 3, 2015
This one’s unsatisfactory. Ideally I’d give a list of all possible pairs of cities that work, but there are probably millions of those, so I just looked for one. Cairo is south-east of Alexandria, so you’d expect one of the 2 cities outside Egypt to be to the south-west. The problem is, there’s a big huge expanse of nothingness that way.
After much scrolling, I finally found Agadez, in Niger. Next I had to find a city to the north-east of Egypt so that the great circle path between the two goes between Alexandria and Cairo. You can’t do this just by drawing lines out of Agadez – the shortest path between two points on the globe isn’t a straight line on a map projection – so I searched for a tool that would draw great circles for me. I found a tool called Great Circle Mapper, which performed admirably. Great circles are vital for planning air routes, so the tool only takes airport names. Fortunately, Agadez has an airport! After a few false starts, I found that the path between Agadez and Tel Aviv separates Alexandria and Cairo:
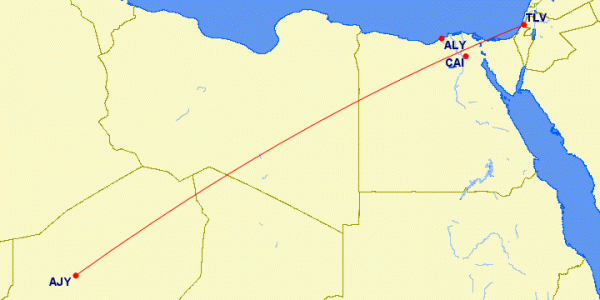
If I’d been really obtuse, I would’ve found a city south-west of Agadez so that the long route between them separates the two Egyptian cities, but I’m fairly happy with the answer I got.
But Wolfram|Alpha can answer: 23.5S 46.4W to 56.8N 60.6E
average speed of an aircraft leaving New York at 3pm EST and arriving in Los Angeles at 6pm PST
— Wolfram|Alpha Can't (@wacnt) January 26, 2015
Wolfram|Alpha really should be able to do this one. You just need to find the distance between New York and Los Angeles airports, and divide by the difference in time betwen 6pm PST and 3pm EST.
The Great Circle Mapper tool quickly told me that JFK-LAX is 2475 miles, and since PST is three hours behind EST, the flight took 6 hours. That means the aircraft’s average speed was $2475 \div 6 = 412.5$mph.
But Wolfram|Alpha can answer: convert greenwich mean time to eastern time
the sentence in Othello whose word count increases by the most when translated into French
— Wolfram|Alpha Can't (@wacnt) January 27, 2015
I had a really good go at this, but failed. I got English and French versions of Othello from Project Gutenberg, which were luckily in very similar formats, did some Vim magic to make them line up even better, and set Python on it. My plan was to compare each line of dialogue, hoping that the number of sentences would almost always be the same in each translation, and do word counts.
Unfortunately, some very slight differences meant that the lines failed to line up somewhere in Act II, and I decided life was too short to set about trying to fix it. This one’s just about possible if you interpret the query a certain way (and Wolfram|Alpha certainly doesn’t mind doing that), but I don’t blame Wolfram|Alpha for not being able to do it.
But Wolfram|Alpha can answer: On the Origin of Species most frequent capitalized words
number of words between "landslide" and "Beelzebub" in Bohemian Rhapsody
— Wolfram|Alpha Can't (@wacnt) January 22, 2015
This is, I think, the quintessence of a Wolfram|Alpha show-off question: completely pointless, a bit amusing, but well-defined and generalisable. Solving it is really simple: find the lyrics to Bohemian Rhapsody, find the word “landslide”, find the word “Beelzebub”, and count the words in between.
I got the lyrics very easily, and then wrote some Python to split it up into words and find my answer:
import re
bohemian_rhapsody = re.sub(r'[?!.,]','',bohemian_rhapsody)
words = re.split(r'\s+',bohemian_rhapsody)
print(words.index("Beelzebub")-words.index("landslide"))
> 279
I’ve just realised that the question asked for the number of words between ‘landslide’ and ‘Beelzebub’, so the answer is actually 278. This bug will be fixed in CP version 2.0.
But Wolfram|Alpha can answer: word cloud for Bohemian Rhapsody
missing digit in ISBN 0201896?34
— Wolfram|Alpha Can't (@wacnt) January 23, 2015
This is the last question I answered. Wolfram|Alpha really really should be able to do this. An ISBN code is 9 arbitrary digits, followed by a check digit. You find the check digit by multiplying each of the preceding numbers by $10 \dots 2$, respectively, and taking the result modulo $11$. The eighth digit is missing, so it would be multiplied by $3$ in the check digit calculation.
Some very simple Python found the answer:
isbn = '0201896?34'
t = 0
for d,i in zip(isbn[:-1],range(10,1,-1)):
if d!='?':
t += int(d)*i
m = t%11
target = int(isbn[-1])
missing_index = isbn.index('?')
missing_mult = 10-missing_index
for a in range(11):
if (missing_mult*a+t)%11==target:
print(a)
> 7
But Wolfram|Alpha can answer: ISBN 1-5795-5008-8
Conclusion
So, what did I learn in my evening as a human computational knowledge engine? Each of the questions took about 20 minutes to answer, on average. The solution almost always involved finding a little bit of machine-readable information on the internet and plugging it into a very simple algorithm. Apart from the Othello question, I don’t think I answered a single question that Wolfram|Alpha couldn’t be taught to, if someone could be bothered.
That’s the problem with Wolfram|Alpha – most of the types of question it can answer have to be programmed in individually. I’m not at all convinced that it will eventually reach a point of sufficient complexity that it can devise the solutions to these kinds of questions itself. It’s very useful anyway, and I’d definitely miss it if it wasn’t there. I suppose it’s a bit like the UNIX of recreational maths – common tasks have been abstracted and automated, so nobody needs to reinvent the wheel while getting on with whatever new thing they’re trying to do.
For myself, I had a lot of fun answering these questions. Compared with Project Euler, the more popular geek brainstretcher, it was both a lot easier and a lot more interesting. If you want a good challenge of your lateral thinking and programming skills, I heartily recommend taking on Wolfram|Alpha at its own game!
The “Norwegian flag” problem doesn’t have an integer answer, since 1000 isn’t divisible by 18. (The Norwegian flag is 18 units tall with the vertical ratio of red:white:blue:white:red being 7:1:2:1:7.)
Did you try to find info about the birth rate in Vatican City? I would think Italy-Vatican City would have the highest ratio, although I would agree that that’s not really in the spirit of the question. A 20-second Google search didn’t give me an actual number for the birth rate in Vatican City, so I’m not sure if it would actually work. Italy has a very low birth rate, and Vatican City does have some residents who are not priests/nuns/etc.
The Vatican City doesn’t contain a hospital, so that along with the very low number of resident women mean that its birth rate is zero.
I think the high dot:dash ratio in the Morse Code one is because Morse Code is optimised for speed and dots are faster than dashes. That might have the effect of making common letters dot-heavy, but that isn’t really a full explanation.
In the letters A-Z, there are 43 dots to 38 dashes (counted by eye). That’s a slight advantage, but not enough.
I think it makes sense that common letters would be more dot-heavy.
You mentioned a resemblance to Project Euler with the 7-segment LED question… Problem 315 asks a similar question about segment flips, though with more constraints and complexity.
I’ve just noticed that my word list seems to be missing “synonymous”. Weird!
… and David Cushing has pointed out that a repunit is a string of 1s, not just any digit – I was thinking of a repdigit. My answer is now early December 1824, when the population was 1111111111.
I decided to try to be a bit more thorough with the Alexandria/Cairo question so I constrained it to just capital cities, as defined by one specific list on Wikipedia, and to write a script to search for all possible pairs.
It found 213 such pairs of capitals, including London (UK) – Victoria (Seychelles), which just slips through the Alexandria/Cairo gap at a very grazing angle, and my personal favourite, Dakar (Senegal) – Dhaka (Bangladesh), which has a nice symmetry both geographically and linguistically.
My script and results are here and a picture is here.
what is CP? We need a vocabulary index…
CP is me! (I added the Lawson- when I got married)